

This is the second in a series of posts in which I share my advice for candidates interviewing for tech companies, drawing on my experience as an engineer and interviewer at Google. If you haven’t already, take a look at the introduction to this series.
Before I start, a disclaimer: while interviewing candidates is one of my professional responsibilities, this blog represents my personal observations, my personal anecdotes, and my personal opinions. Please don’t mistake this for any sort of official statement by or about Google, Alphabet, or any other person or organization.
This was the first problem I used during my interviewing career, and it was also the first to leak and get banned. I like it because it hits number of sweet spots:
- It’s easy to state and understand.
- It has a number of solutions, each requiring varying degrees of algorithms and data structures knowledge. Also, a little bit of insight goes a long way.
- Each solution can be implemented in relatively few lines, making it perfect for a time-constrained environment.
If you’re a student or otherwise applying to tech jobs, my hope is that you’ll come away from reading this with a better understanding of what to expect from interview problems. If you’re an interviewer, I’d like to share my thought process and stylistic approach to interviewing, the better to inform others and solicit comments.
Note I’ll be writing code in Python. I like Python because it’s easy to learn, compact, and has an absolutely massive standard library. Candidates like it, too: even though we impose no language constraints, 90% of people I interview use Python. Also I use Python 3 because c’mon, it’s 2018.
Join our Discord to discuss this problem with the author and the community!
The Question
Imagine you place a knight chess piece on a phone dial pad. This chess piece moves in an uppercase “L” shape: two steps horizontally followed by one vertically, or one step horizontally then two vertically:

Suppose you dial keys on the keypad using only hops a knight can make. Every time the knight lands on a key, we dial that key and make another hop. The starting position counts as being dialed.
How many distinct numbers can you dial in N hops from a particular starting position?
Discussion
Every interview I conduct basically breaks down into two parts: first we find an algorithmic solution and then the candidate implements it in code. I say “we” find a solution because I’m not a mute spectator: 45 minutes is not a lot of time to design and implement anything under the best circumstances, never mind under pressure. I let candidates take the lead in the discussion, generating ideas, solving instances of the problem, etc., but I’m more than happy to give a nudge in the right direction. The better the candidate, the fewer hints I tend to have to give, but I have yet to see a candidate who required no input from me at all.
I should underscore this, because it’s important: as an interviewer, I’m not in the business of sitting back and watching people fail. I want to write as much positive feedback as I can, and I try to give you opportunities to allow me to write good things about you. Hints are my way of saying “okay, I’m gonna give this bit to you, but only so you can move on and show me what you’ve got on the other parts of the question.”
With that being said, your first action after hearing the question should be stepping up to the whiteboard and solving small instances of the problem by hand. Never dive right into code! Solving small instances lets you spot patterns, observed and edge cases, and also helps crystallize a solution in your head. As an example, suppose you start on 6 and have two hops to make. Your sequences will be…
- 6–1–8
- 6–1–6
- 6–7–2
- 6–7–6
- 6–0–4
- 6–0–6
…for a total of six sequences. If you’re following along, try taking a pencil and paper and deriving these. This doesn’t translate well into a blog post, but trust me when I say there’s something magical about working out a problem by hand that leads to many more insights than just staring at it and thinking quietly.
With all that said, you may have a solution forming in your head. But before we get there…
Level 0: Getting the Next Hop
One of the surprises I had when I started using this problem is how often candidates get stuck on computing the keys to which we can hop from a given position, also known as the neighbors. My advice is: when in doubt, write an empty placeholder and ask the interviewer if you can implement it later. This problem’s complexity does not lie in the neighbor computation; I’m paying attention to how well you count full numbers. Any time spent on neighbor computation is effectively wasted.
I would accept “let’s assume there’s a function that gives me the neighbors” along with the following stub. Of course, I’ll probably ask you to double back and implement this later, but only if we have time. You can simply write a stub like this and move on:
def neighbors(position):
...Also, you don’t really lose much by asking to use a stub: if the question’s complexity is elsewhere I’ll allow it. If not, I’ll ask you to actually implement it. I don’t mind when candidates don’t realize where the complexity of a question lies, especially in the early stages when they might not have fully explored the problem.
As for the neighbors function here, given that it never changes you can simply create a map and return the appropriate value:
NEIGHBORS_MAP = {
1: (6, 8),
2: (7, 9),
3: (4, 8),
4: (3, 9, 0),
5: tuple(), # 5 has no neighbors
6: (1, 7, 0),
7: (2, 6),
8: (1, 3),
9: (2, 4),
0: (4, 6),
}
def neighbors(position):
return NEIGHBORS_MAP[position]Level 1: Recursively Generating Numbers
Anyway, on to the solution. Perhaps you’ve already noticed this problem can be solved by enumerating all possible numbers and counting them. You can use recursion to generate these values:
def yield_sequences(starting_position, num_hops, sequence=None):
if sequence is None:
sequence = [starting_position]
if num_hops == 0:
yield sequence
return
for neighbor in neighbors(starting_position):
yield from yield_sequences(
neighbor, num_hops - 1, sequence + [neighbor])
def count_sequences(starting_position, num_hops):
num_sequences = 0
for sequence in yield_sequences(starting_position, num_hops):
num_sequences += 1
return num_sequencesThis works, and it’s a common starting point I saw in interviews. Notice, however, that we generate the numbers and never actually use them. This problem asks for the count of numbers, not the numbers themselves. Once we count a number we never revisit it. As a general rule of thumb, I recommend paying attention to when your solution computes something it doesn’t use. Often you can cut it out and get a better solution. Let’s do that now.
Level 2: Counting Without Counting
How can we count phone numbers without generating them? It can be done, but not without an additional insight. Notice how the count of numbers that can be generated from a given starting position in N hops is equal to the sum of the counts of hops that can be generated starting from each of its neighbors in N-1 hops. Stated mathematically as a recurrence relation, it looks like this:
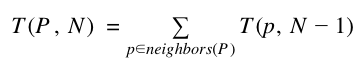
This is intuitively obvious when you consider what happens with one hop: 6 has 3 neighbors (1, 7, and 0) and in zero hops you can reach one number for each, so you can only dial three numbers.
How does one arrive at this insight, you might ask? If you’ve studied recursion, this should become evident after some exploration on the whiteboard. Many candidates who’ve practiced recursion immediately notice this problem breaks down into smaller subproblems, which is a dead giveaway. If you’re in an interview with me and you can’t seem to arrive at this insight, I will usually give hints to help get you there, up to and including outright giving it away if prodding fails.
Once you have this insight in hand, you can already move forward and solve this problem again. There are a number of implementations that use this fact, but let’s start with the one I see most often in interviews: the naive recursive approach:
from neighbors import neighbors
def count_sequences(start_position, num_hops):
if num_hops == 0:
return 1
num_sequences = 0
for position in neighbors(start_position):
num_sequences += count_sequences(position, num_hops - 1)
return num_sequences
if __name__ == '__main__':
print(count_sequences(6, 2)) That’s it! Combine this with a function to compute the neighbors and you’ve produced a working solution! At this point, you should pat yourself on the back. If you scroll down you’ll notice we’ve still got a lot of ground to cover, but this point is a milestone. Producing any working solution already sets you apart from a surprising number of candidates.
This next question is one you’re going to be hearing a lot from me: what is the Big-O complexity of this solution? For those who don’t know, Big-O complexity is (informally) a sort of shorthand for the rate at which the amount of computation required by a solution grows as a function of the size of the input. For this problem, the size of the input is the number of hops. If you’re interested in the proper mathematical definition, you can read more here.
For this implementation, every call to count_sequences() recursively calls count_sequences() at least twice, because each key has at least two neighbors. Since we recurse a number of times equal to the desired number of hops, and the number of calls to count_sequences() at least doubles with each call, we’re left with a runtime complexity of at least exponential time.
This is bad. Asking for an additional hop will double, if not triple, the runtime. For small numbers like 1 through maybe 20 this is acceptable, but as we ask for larger and larger numbers of hops, we hit a wall. For instance, 500 hops would require until well after the heat death of the universe to complete.
Level 3: Memoization
Can we do better? Using only the mathematical relation above and nothing else, not really. One of the reasons I love this problem, though, is it features layers of insight that yield more and more efficient solutions. To find the next one, let’s map out the function calls this function makes. Let’s consider the case of count_sequences(6, 4). Note I use C as the function name for brevity:
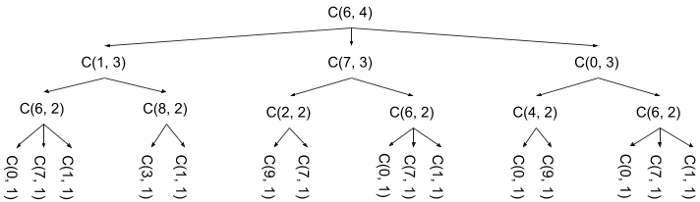
You may notice something peculiar: the C(6, 2) call is performed three times, and each time it performs the same computation, and returns the same value. The crucial insight here is that these function calls repeat, each time returning the same value. After you compute their result once there’s no need to recompute them.
If you’re wondering how you’re supposed to arrive at this, the easiest way is through good old-fashioned whiteboarding: staring at this problem statement in the abstract is nice, but I always encourage candidates to throw a sample solution up on the board. Solving out a problem like this and drawing the tree like I did above will see you writing the subtree for C(6, 2) multiple times, which you’re sure to notice. This is sometimes enough of an insight to allow candidates to bypass solutions 1 and 2 altogether and jump straight to this stage. Needless to say, that’s a huge time save in an interview where you only have 45 minutes to solve a problem.
Armed with this insight, how do we solve this problem? We can use memoization (not memorization), which basically means we record results of function calls we’ve seen before and use those instead of redoing the work. This way, when we encounter a place in the call graph where we would unnecessarily recompute an entire subtree, we instead immediately return the result we already computed. Here’s an implementation:
def count_sequences(start_position, num_hops):
cache = {}
def helper(position, num_hops):
if (position, num_hops) in cache:
return cache[ (position, num_hops) ]
if num_hops == 0:
return 1
else:
num_sequences = 0
for neighbor in neighbors(position):
num_sequences += helper(neighbor, num_hops - 1)
cache[ (position, num_hops) ] = num_sequences
return num_sequences
res = helper(start_position, num_hops)
return resAlright, what’s the runtime complexity (Big-O) now? That’s tougher to answer. For the previous implementation, computing the runtime was as simple as counting the number of times the recursive function was called, which was always two or three times per call. This time counting is more complicated because the recursive call is guarded by a conditional. On the face of it there’s no obvious way to count function calls.
We can solve this mystery by instead looking at the cache. Each function call’s result is stored in the cache, and it’s inserted there exactly once. This allows us to reframe the question as “how does the size of the cache grow with the size of the input?” Given that the cache is keyed by position and number of hops, and there are exactly ten positions, we can conclude that the cache grows in direct proportion to the number of requested hops. This follows from the pigeonhole principle: once we have an entry in the cache for every combination of position and jump count, all calls will hit the cache rather than result in a new function call.
Linear time! That’s not bad. In fact, it’s remarkable: the addition of a simple cache changed the algorithm’s runtime from exponential to linear. On my venerable old MacBook Air, the recursive implementation takes about 45 seconds to run for twenty hops. This implementation can handle 500 hops in around 50 milliseconds. Not bad at all.
So we’re done right? Well, not quite. This solution has two drawback, one major(ish) and one minor. The major-ish drawback is that it’s recursive. Most languages place limits on the maximal size of their call stacks, which means there’s always a maximal number of hops an implementation can support. On my machine it fails after about 1000 hops. This is a major-ish limitation rather than a major one because any recursive function can be re-implemented in an iterative way, but still, it’s a hassle. As for the minor limitation, that actually leads us into the next solution…
Level 4: Dynamic Programming
The minor limitation of the recursive memoizing solution is clear when you look at the recurrence relation from above:
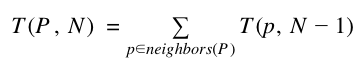
Notice that the results for N hops depend only on the results for calls with N-1 hops. Meanwhile, the cache contains entries for every (nonzero) number of hops. I call this a minor issue because it doesn’t actually cause any real problems, given that the cache grows only linearly with the number of hops. Requiring linear space isn’t the end of the world, but still, it’s inefficient.
What gives? Again, the result is clear when you look at a written-out solution and the code. Notice that the code starts with the largest number of hops and recurses directly down to the smallest:
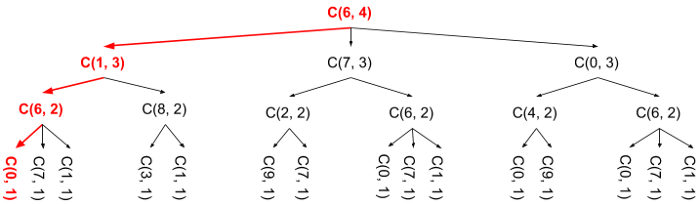
If you imagine the entire function call graph as a sort of virtual tree, you’ll quickly see we’re performing a depth-first traversal. This is fine, it gives a proper solution, but it doesn’t take advantage of the shallow dependency property I pointed out above.
Can you perform a breadth-first traversal instead, where you start at the top and “visit” function calls for N-1 hops only after you’ve visited those for N hops? Sadly, no. The values of function calls with nonzero hops absolutely require the values from smaller hop counts, so you won’t get any results until you reach the zero-hop layer and start returning numbers rather than additional function calls (note the zero-hop layer isn’t depicted here).
You can however, reverse the order: visit layers with N hops only after you’ve visited layers with N-1 hops. Those of you who studied or are studying discrete mathematics will recognize all the necessary ingredients for an induction: we know that the values of zero-hop function calls are always one (the base case). We also know how to combine N-1 hop values to get N hop values, using the recurrence relation (the inductive step). We can start with a base case of zero hops and induce all values greater than zero. Here’s an implementation:
def count_sequences(start_position, num_hops):
prior_case = [1] * 10
current_case = [0] * 10
current_num_hops = 1
while current_num_hops <= num_hops:
current_case = [0] * 10
current_num_hops += 1
for position in range(0, 10):
for neighbor in neighbors(position):
current_case[position] += prior_case[neighbor]
prior_case = current_case
return current_case[start_position] So what’s better about this version than the recursive, depth-first solution? Not a ton, but it has a few benefits. First off, it’s not recursive, meaning it can run for extremely large values without crashing. Second off, it uses constant memory, because it only ever needs two arrays of fixed size rather than the ever-growing cache of the memoization solution. Finally, it’s still linear time: I can compute 200,000 hops in just under twenty seconds.
Assessment
So we’re done, right? Pretty much. Designing and implementing a linear time, constant space solution in a job interview is a very good result. When I was using this question, I gave candidates who provided the dynamic programming solution an excellent rating.
What about the other solutions, you might ask? Unfortunately it’s impossible to rate an abstract candidate. Interviews are chaotic things; they can start late, people can be nervous, and they often arrive at insights and solutions late in the session, leaving them with little time to code anything. There’s also a conversation happening: I pay attention to how well the candidate communicates their thoughts and incorporates ideas and feedback. I always take these factors into account before making a hire/no-hire recommendation, and you just can’t do that in the abstract.
Instead of potential recommendations, I’ll focus on the things I’d like to be able to say. When assessing algorithms and data structures, I want to say something like “TC (The Candidate) explored the problem and produced a solution that addressed all edge cases, and improved the solution when presented with its shortcomings. In the end, they arrived at an optimal solution.” I also want to be able to say “TC chose appropriate data structures for the solution, and correctly answered questions about the Big-O of their solution’s runtime and space requirements.”
When assessing coding, my ideal statement would be “TC quickly and concisely translated their ideas into code. The code uses standard language constructs and is easy to read. All edge cases are addressed, and TC walked through their code to debug it and verify it’s correct.” For entry-level roles I give bonus points if there’s some sort of testing, but more experienced roles I penalize candidates who don’t at least list relevant test cases.
As for speed of progress, I’d love to be able to say “TC drove the problem solving process: they developed most of their own solution, and were able to identify and address shortcomings without my pointing them out. TC required only minimal hints to get them moving in the right direction.”
Anyone I can say these things about gets a “Strong Hire” in my book. However, “Hire” and “Leaning Hire” are also positive endorsements. If you come up short in one area but shine in another then I can probably still justify a positive recommendation.
Wrapping Up
This problem might seem daunting, especially given that this post has become as long as it has. Keep in mind, however, that this post is purposefully much more thorough than any interview will ever be. I’m not laying out everything I expect to see, I’m dissecting a problem into its finest details to leave nothing out.
To that end, here is a list of skills this question covers and habits you ought to develop:
- Always start by solving a small instance of the problem by hand. In this problem the recurrence relation and the repetition of function calls become much more obvious when you hand-solve a problem.
- Pay attention to when your solution is computing things you don’t need, like how the naive counting solution generates the sequences but doesn’t actually use them. Reducing unnecessary computation can often provide simpler solutions, if not open the door to more efficient ones.
- Know your recursion. It’s almost useless in most production code because it blasts through the stack, but it’s a very powerful algorithm design tactic. Recursive solutions can often be adapted and improved: the difference between the exponential time naive solution and the linear time nearly-optimal memoization solution is minimal.
- Know your Big-O analysis! You’re practically guaranteed to be asked this at some point during the interview process.
- Always be on the lookout for opportunities to memoize. If your function is deterministic and you’ll be calling it multiple times with the same inputs, your solution may benefit from memoization.
- Find and write out the recurrence relation. In this case writing it out makes it obvious that counts for N hops depend only on counts for N-1 hops.
If you liked this post, join the discussion on our discord! That's there I hang out, answer questions, and take suggestions for topics for future posts.
But Wait, There’s More!
Okay, so I said we were done, but it turns out this problem has one more solution. In all my time interviewing with this problem I’ve never seen anyone provide it. I didn’t even know it existed until one of my colleagues came back to his desk with a shocked look on his face and announced he had just interviewed the best candidate he’d ever seen.
I’ll post a detailed follow-up soon, but in the meantime I’ll leave you all to wonder how this problem can be solved in logarithmic time…
Update: you can check out the rest of the series here: